elasticsearch, kibana
背景
個人的には Data visualization に興味があり、数年前には Visual Complexity を買って読んでみたり、 d3.js を使ったwebサイトなども作成したことがありました。
Data visualization の面白さは、
- なんとなくそうかなと思っていたことを具体的な数値で比較できる(その結果、思っていたよりも変わっていないことも確認できる)
- 事前知識の異なる人にも何となく現状を理解してもらい、意思決定に役立たせることが可能
という点にあるなと思います。
ただ、データの整形などの準備に時間がかかったり、ツールによって表現できる種類が限られていたりするので、そこら辺を手際よく使いこなせるとビジネス的にも美味しいわけです。
むろん、大概のデータは Excel で済むことがあるので、手っ取り早くグラフ化したい場合は Excel を使ったり、ネットワークグラフや地図グラフであれば、d3.js を使うと簡単に表現できます。
しかし、ログデータを代表とする時系列データは、新しい情報を確認することが重要であるため、Elasticsearch & Kibana のようなツールが必要となってきます。
Elasticsearch と Kibana
Elasticsearch については、gihyoの記事 に概要がまとめられています。Apache Lucene という Javaで動作する全文検索ライブラリをベースにしているのが特徴です。Lucene は英語の検索を元に考えられているため、空白による単語の区切りがない日本語では、形態素解析してから検索するプラグインの導入(Kuromoji, lucene-gosen)が必要となるようです。
Kibana はこちらのブログ にも説明されていますが、時系列データの visualization ツールです。視覚化する際に範囲検索や曖昧な検索するために、Elasticsearchを利用するのですね。
セットアップ
elasticのサイトにチュートリアルがあるため、こちらを行います。
2016/12/25 時点で最新バージョン(Elasticseach 5.1.1, Kibana 5.1.1) を使います。
Elasticsearch(& Java SE)のインストールと起動
Homebrew をインストールして、brew コマンド経由でパッケージをインストールしていきます(MacPortsぇ…)。
Elasticsearch を brew installしようとすると、Mac にはデフォルトで Javaのランタイムが入っていないので、
1
| elasticsearch: Java 1.8+ is required to install this formula.JavaRequirement unsatisfied!
|
というエラーが出ます。そこで、oracleのページ から Java SE 8 をダウンロードして、インストールします。
そして、Elasticsearchをインストールします。
1
| brew install elasticsearch
|
インストールが無事に終わり、Elasticsearchを起動すると以下のようなログが表示されます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| $ elasticsearch
[2016-12-25T00:54:08,948][INFO ][o.e.n.Node ] [] initializing ...
[2016-12-25T00:54:09,005][INFO ][o.e.e.NodeEnvironment ] [aHzQ2Yk] using [1] data paths, mounts [[/ (/dev/disk1)]], net usable_space [403.2gb], net total_space [464.7gb], spins? [unknown], types [hfs]
[2016-12-25T00:54:09,006][INFO ][o.e.e.NodeEnvironment ] [aHzQ2Yk] heap size [1.9gb], compressed ordinary object pointers [true]
[2016-12-25T00:54:09,008][INFO ][o.e.n.Node ] node name [aHzQ2Yk] derived from node ID [aHzQ2YkXSXiao7InpiaL8g]; set [node.name] to override
[2016-12-25T00:54:09,011][INFO ][o.e.n.Node ] version[5.1.1], pid[40589], build[5395e21/2016-12-06T12:36:15.409Z], OS[Mac OS X/10.11.6/x86_64], JVM[Oracle Corporation/Java HotSpot(TM) 64-Bit Server VM/1.8.0_111/25.111-b14]
[2016-12-25T00:54:09,725][INFO ][o.e.p.PluginsService ] [aHzQ2Yk] loaded module [aggs-matrix-stats]
[2016-12-25T00:54:09,725][INFO ][o.e.p.PluginsService ] [aHzQ2Yk] loaded module [ingest-common]
[2016-12-25T00:54:09,725][INFO ][o.e.p.PluginsService ] [aHzQ2Yk] loaded module [lang-expression]
[2016-12-25T00:54:09,725][INFO ][o.e.p.PluginsService ] [aHzQ2Yk] loaded module [lang-groovy]
[2016-12-25T00:54:09,726][INFO ][o.e.p.PluginsService ] [aHzQ2Yk] loaded module [lang-mustache]
[2016-12-25T00:54:09,726][INFO ][o.e.p.PluginsService ] [aHzQ2Yk] loaded module [lang-painless]
[2016-12-25T00:54:09,726][INFO ][o.e.p.PluginsService ] [aHzQ2Yk] loaded module [percolator]
[2016-12-25T00:54:09,726][INFO ][o.e.p.PluginsService ] [aHzQ2Yk] loaded module [reindex]
[2016-12-25T00:54:09,726][INFO ][o.e.p.PluginsService ] [aHzQ2Yk] loaded module [transport-netty3]
[2016-12-25T00:54:09,726][INFO ][o.e.p.PluginsService ] [aHzQ2Yk] loaded module [transport-netty4]
[2016-12-25T00:54:09,727][INFO ][o.e.p.PluginsService ] [aHzQ2Yk] no plugins loaded
[2016-12-25T00:54:11,369][INFO ][o.e.n.Node ] initialized
[2016-12-25T00:54:11,369][INFO ][o.e.n.Node ] [aHzQ2Yk] starting ...
[2016-12-25T00:54:11,518][INFO ][o.e.t.TransportService ] [aHzQ2Yk] publish_address {127.0.0.1:9300}, bound_addresses {[fe80::1]:9300}, {[::1]:9300}, {127.0.0.1:9300}
[2016-12-25T00:54:14,578][INFO ][o.e.c.s.ClusterService ] [aHzQ2Yk] new_master {aHzQ2Yk}{aHzQ2YkXSXiao7InpiaL8g}{2NtgXBlDRCqme2oBZAW99g}{127.0.0.1}{127.0.0.1:9300}, reason: zen-disco-elected-as-master ([0] nodes joined)
[2016-12-25T00:54:14,595][INFO ][o.e.h.HttpServer ] [aHzQ2Yk] publish_address {127.0.0.1:9200}, bound_addresses {[fe80::1]:9200}, {[::1]:9200}, {127.0.0.1:9200}
[2016-12-25T00:54:14,595][INFO ][o.e.n.Node ] [aHzQ2Yk] started
[2016-12-25T00:54:14,600][INFO ][o.e.g.GatewayService ] [aHzQ2Yk] recovered [0] indices into cluster_state
|
Kibanaのインストール
Kibanaもbrewでインストールします。
インストール後に、Kibanaを起動すると以下のようなログが表示されます。
1
2
3
4
5
6
7
8
9
10
11
| $ kibana
log [15:54:21.151] [info][status][plugin:kibana@5.1.1] Status changed from uninitialized to green - Ready
log [15:54:21.193] [info][status][plugin:elasticsearch@5.1.1] Status changed from uninitialized to yellow - Waiting for Elasticsearch
log [15:54:21.212] [info][status][plugin:console@5.1.1] Status changed from uninitialized to green - Ready
log [15:54:21.338] [info][status][plugin:timelion@5.1.1] Status changed from uninitialized to green - Ready
log [15:54:21.342] [info][listening] Server running at http://localhost:5601
log [15:54:21.343] [info][status][ui settings] Status changed from uninitialized to yellow - Elasticsearch plugin is yellow
log [15:54:26.370] [info][status][plugin:elasticsearch@5.1.1] Status changed from yellow to yellow - No existing Kibana index found
log [15:54:26.582] [info][status][plugin:elasticsearch@5.1.1] Status changed from yellow to green - Kibana index ready
log [15:54:26.583] [info][status][ui settings] Status changed from yellow to green - Ready
|
このとき、elasticsearch を起動していないと、以下のエラーが発生します。
1
2
| log [15:43:23.426] [warning][elasticsearch] Unable to revive connection: http://localhost:9200/
log [15:43:23.426] [warning][elasticsearch] No living connections
|
デフォルトの設定で、Kibana は localhost:9200 を見ているので、9200ポートにElasticsearchがないと REST API による連携が行えないということですね。
(最近、Cloud Foundry cliやその他のライブラリでもGUIではなく、APIとして REST を提供する例をよく目にします。何だかんだhttpsで暗号化できたり、どの言語からも使えたりするのが便利です)
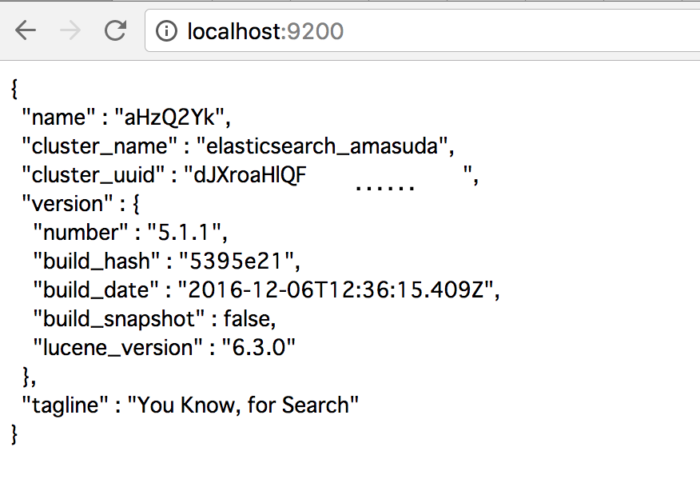
ElasticsearchとKibanaにブラウザからアクセスしてみる
まずは Elasticsearch (http://localhost:9200)
Kibana (http://localhost:5601)
サンプルデータを入力
さて、elasticのチュートリアル Getting Started からサンプルデータを取得します。今回は、サイズがあまり大きくない Shakespeare のデータを使ってみました(ログを試してみたい方は別のログデータセットがあります)。
1
2
3
4
5
6
7
8
9
10
11
| head -n 20 Downloads/shakespeare.json
{"index":{"_index":"shakespeare","_type":"act","_id":0}}
{"line_id":1,"play_name":"Henry IV","speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"}
{"index":{"_index":"shakespeare","_type":"scene","_id":1}}
{"line_id":2,"play_name":"Henry IV","speech_number":"","line_number":"","speaker":"","text_entry":"SCENE I. London. The palace."}
{"index":{"_index":"shakespeare","_type":"line","_id":2}}
{"line_id":3,"play_name":"Henry IV","speech_number":"","line_number":"","speaker":"","text_entry":"Enter KING HENRY, LORD JOHN OF LANCASTER, the EARL of WESTMORELAND, SIR WALTER BLUNT, and others"}
{"index":{"_index":"shakespeare","_type":"line","_id":3}}
{"line_id":4,"play_name":"Henry IV","speech_number":1,"line_number":"1.1.1","speaker":"KING HENRY IV","text_entry":"So shaken as we are, so wan with care,"}
{"index":{"_index":"shakespeare","_type":"line","_id":4}}
|
さて、まずはデータの形式を Elasticsearch に教える必要があります。ターミナルから以下のコマンドを入力します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| $ curl -XPUT http://localhost:9200/shakespeare -d '
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "string", "index" : "not_analyzed" },
"play_name" : {"type": "string", "index" : "not_analyzed" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}
'
|
上記コマンドは、jsonデータにデフォルトでどんなプロパティがあるのかを定義しています。 not_analyzed は “speaker” キーにデータが複数入っていても1つの塊として認識するオプションです。
非構造データの場合は指定するとよいのでしょう。
余談ですが、位置情報のための型も用意されており、 “type”: “geo_point” を指定すると地図に緯度経度の表示します。
さて、サンプルデータをまとめて Elasticsearch にアップロードするため、
1
| curl -XPOST 'localhost:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json
|
を実行します(中のデータがターミナルを流れていきます)。
ちゃんとデータがはいったかどうかは、
1
2
3
4
5
| $curl 'localhost:9200/_cat/indices?v'
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana SxdxNaE7QcmKTybeynsJtw 1 1 1 0 3.1kb 3.1kb
yellow open shakespeare saiUcyyaTUmNxKRgQ0hD8Q 5 1 111396 0 27.9mb 27.9mb
|
で確認できます。
インデックスの指定と Visualize
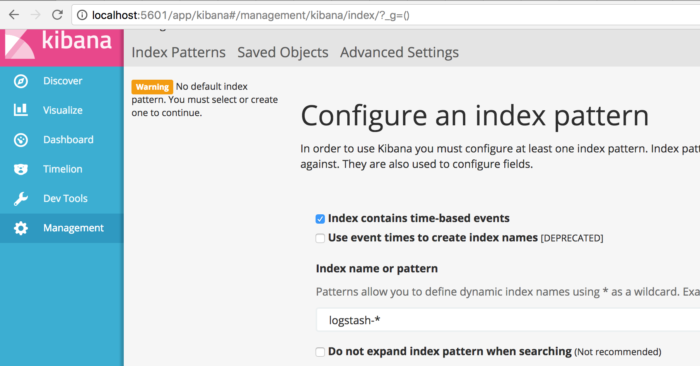
ようやく可視化と言いたいのですが、次はKibanaから Elasticsearchに入れたデータのインデックスを指定する必要があります。
このインデックスの説明が厄介で、初回起動時は何かと思ったのですが、このページ を読んで納得しました。要はjsonデータの “_index” という項目に “log20161225” と入っていたとして、これでフィルタリングをかけられるということですね。 logだと汎用的すぎて正規表現が難しくなるので、区別しやすい_index にしましょう。
Shakespeare データは _index に shakespeare と入っているので、 shake* をインデックスとして指定しましょう。
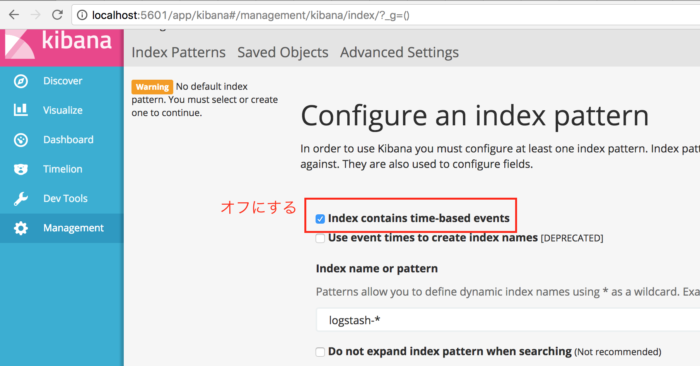
このとき、Shakespeareデータのインデックスに時間情報が含まれていないので、KibanaのGUIで時系列データのチェックボックスをオフにする必要があります
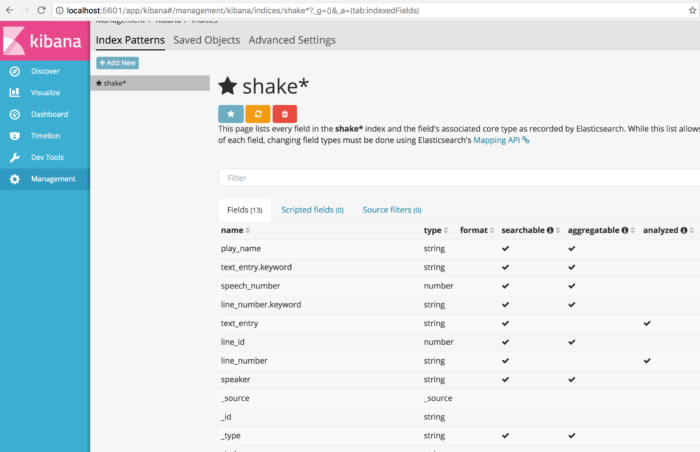
インデックスを指定すると以下のビューになります。
ここまで設定できれば、あとは Discover タブでフィルタリング、Visualize タブで可視化できます。それぞれ色んなオプションがありますが、可視化はこちらのページ が詳しそうです。
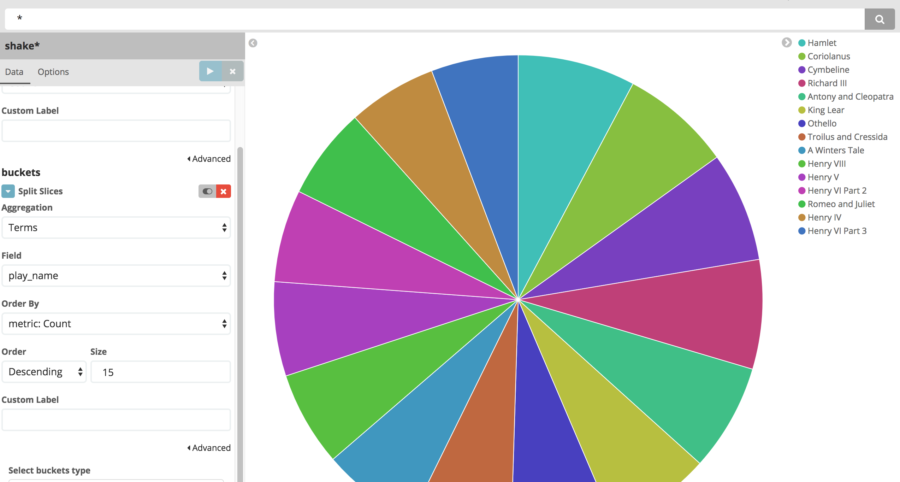
今回は、Pie Chart で Term をバケットとして設定して、劇の名前別に数を見てみました。
まとめ
- Elasticsearch にちゃんとデータの形式を教えてあげる
- Kibana にインデックスを教えてあげる
ことがコツかなと思いました。
余談
こうした時系列データのVisualization tool での競合は、Splunk になるのでしょうか。Splunk は内部的に MapReduceを使っている と説明しているのですが、何かOSSを利用しているのでしょうか。
Splunkも利用する機会が多いので、そのうち記事にするかもですー(Splunkはクエリがいまいち分からないんですよね…)
参考URL
参考図書
[Ad] もし参考になれば 高速スケーラブル検索エンジン ElasticSearch Server