etcd がどのように稼働し、運用するのか
etcd は Kubernetes や分散システムにおいて重要な役割を果たす。 分散システムを実現するにあたり、もっとも難しい課題の1つが、可用性を保ちつついかにデータの一貫性を実現するかだ。
システムの可用性を守ることは難しい話と CAP 定理
例えば、よくあるWebフロントエンド、バックエンドAPI、データベースの構成を考える。
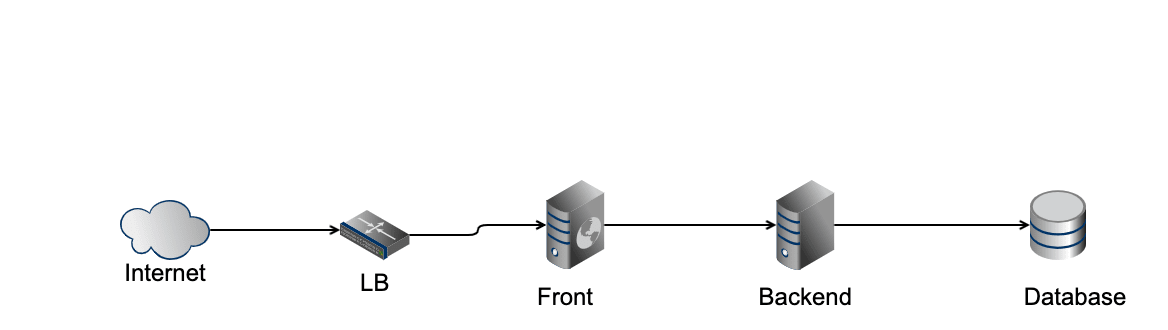
このとき、フロントエンド、バックエンドAPIをステートレス(状態を保持しない、保持していても再起動によりもとの状態に戻ることができる)に作られているとする。
まずこうしたシステムで負荷が上がった場合に、スケールアウトが必要なのはリクエストを処理するフロントエンドのアプリケーションだ。 フロントエンドアプリケーションの前にロードバランサを配置することにより、フロントエンドは数を増やして処理能力を向上できる。
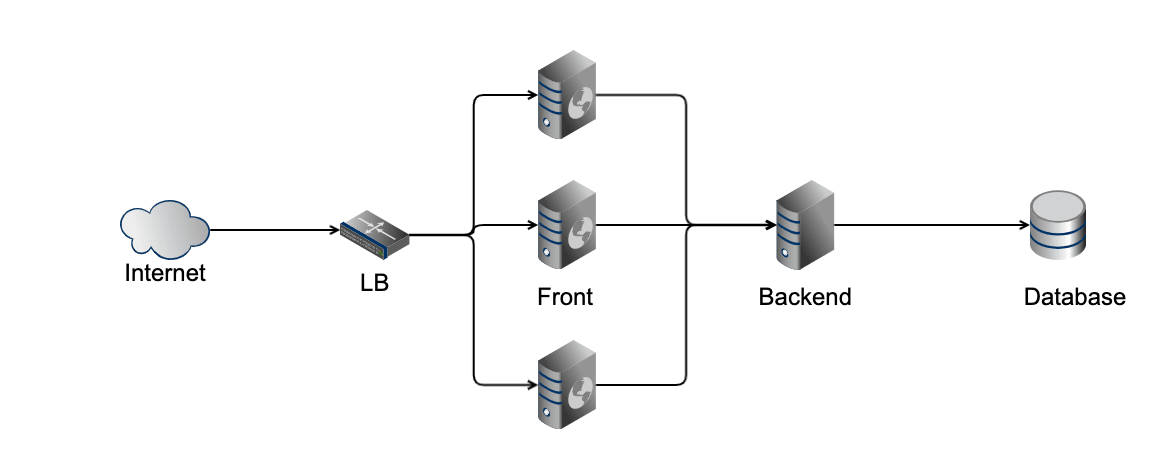
より負荷が増えた時、次に問題になるのがバックエンド API だ。 ここもバックエンド API の前段にロードバランサを用意してスケールアウトさせたり、数を増やしたバックエンド API のいずれかにアクセスをさせることで処理能力を向上できる。
これらのようにステートレスなアプリケーションでは、状態を持たないことで処理のクローンを作り、数が増えても処理結果は変えずに処理能力を高められる。 これが可用性を保つための基本的な考え方だ。
ロードバランサについても内部的に active/standby や active/active 構成をとることで冗長化させているとする。 可用性を考えるときは、様々なレイヤにおいて単一障害点(SPOF) がないかどうかを常に検討する必要がある。 具体的には、せっかく複数のサーバーに処理を分けていても、電源系統が同じだったために電源が落ちて同時に全サーバーが落ちるということがありえたりする。
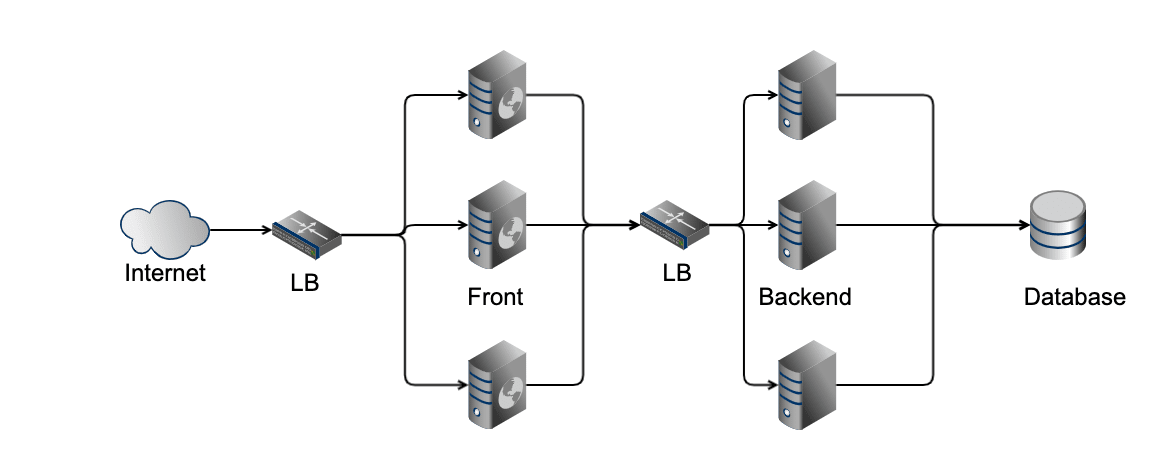
では、データベースはどうだろうか? データベースの前段にロードバランサを配置し、データベースの数を増やしたとする。
このデータベース間で全く同じ情報をコピーしているとする。そうすれば、バックエンド API がデータベースから情報を読み出す時、可用性を保てていそうだ。 問題はデータの書き込みが発生したときだ。
バックエンドAPI がデータベースへの書き込み処理を実施したとすると、どれか1つのデータベースが書き換わることになる。 スケールアウトされたバックエンド API のいくつかが同時に書き込みを行なったらどうだろうか?
「そんなものだめに決まっているだろう」と思われるかもしれない。 実はケースバイケースだ。
どのようなケースで問題にならないかというと、例えば書き込んだデータの一貫性が保たれていなくても良いケースや、書き込まれるデータがお互いに独立していて処理に影響を及ぼさないケースなどだ。
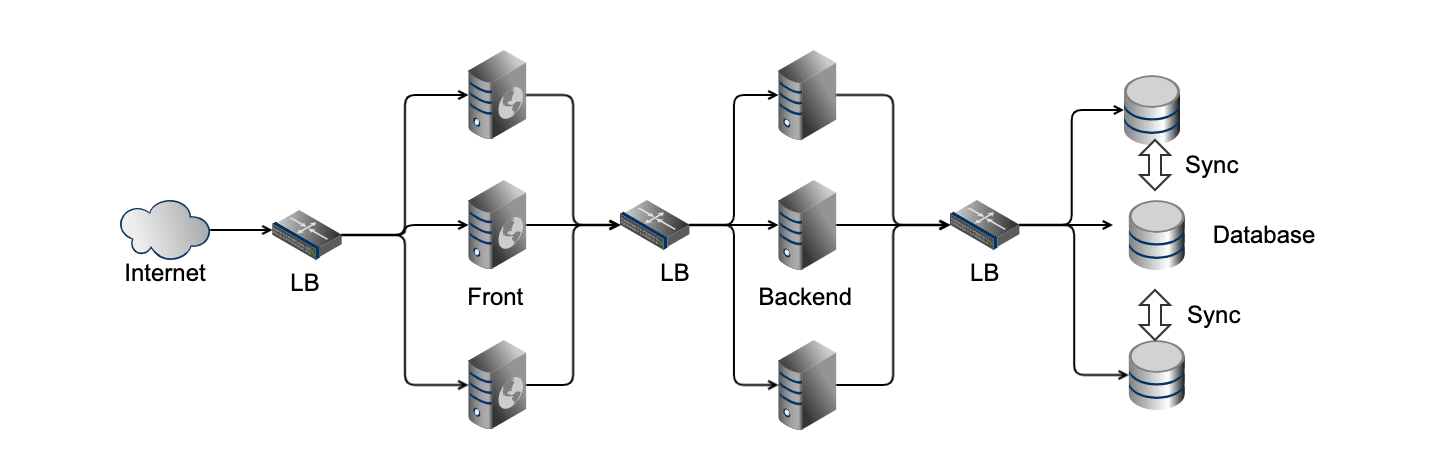
しかし、実際の Web アプリケーションや業務アプリケーションでは、一貫性を必要とする要件であることが多い。 書き込んだデータを読み出したり、順番通りに書き込みが必要なケースでは、図4. だとデータの一貫性を保てなくなり、正常にシステムを動かすことができなくなる。
そこで、データの読み取りはスケールアウトしても問題ないという性質を利用して、下記のようなシステム構成を取ることがある(ただし、データの同期が取れている前提)。
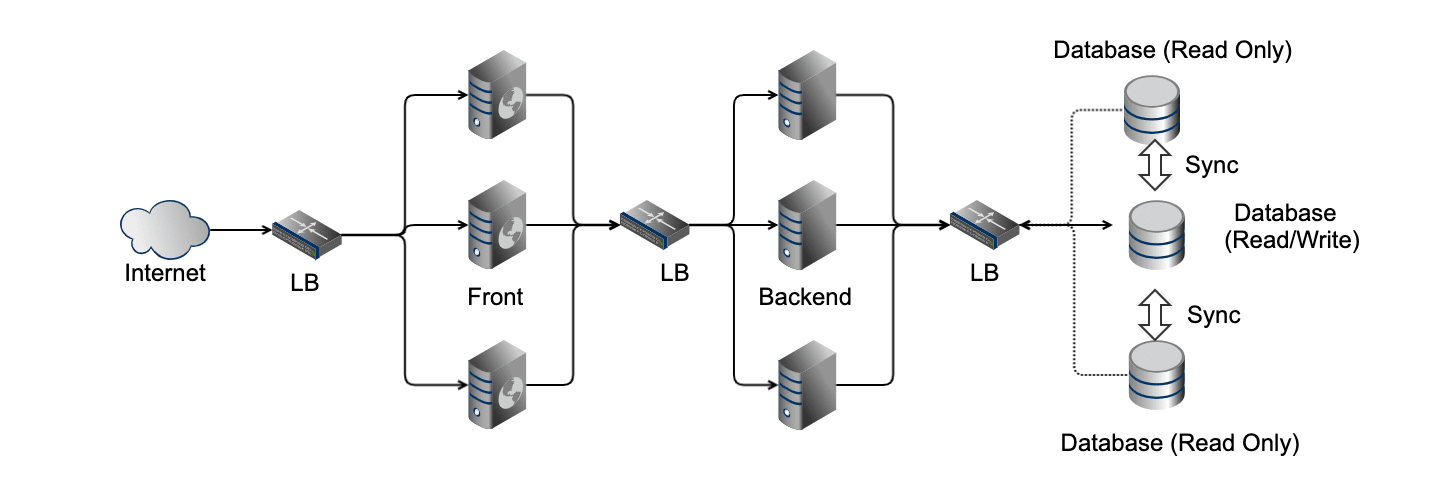
見ての通り、この構成だと Write できる DB は1つだけとなっている。 このように、一貫性を保つためには可用性を一時的に失うことになりそうだ。 このような定理として CAP (Consistency, Availability, Partition Tolerance) 定理 がある。
CAP 定理について、実システムを考慮すると「ネットワークの分断 (Partition) ・異常はどのようなケースでも起こりうるため、可用性か一貫性のどちらかを犠牲にする」ことになる。
- 可用性を重視する場合は、ネットワーク異常が起きた場合も処理を続行(一貫性を一時的に失う)。その後、情報の同期をとることで一貫性を取り戻す。結果整合性(Eventually Consistency) と呼ばれる(例:DNS, 分散KVS(NoSQL) など)
- 一貫性を重視する場合は、ネットワーク異常が起きた場合に処理を停止(可用性を一時的に失う)。異常が解消後、処理を再実行する(例:クラスタRDB など)
参考
etcd と Raft アルゴリズムについて
ここまで、システムの可用性と CAP定理について説明した。
システムを運用していく上で、可用性は常に意識する必要があり、その中でもデータベースのような状態を持つコンポーネントは一貫性を保ちつつ可用性を実現はできない。 そのため、一貫性を保ちながら、いかに可用性の失われる時間を短くするかが鍵となる。 (最近では 東証のシステム障害、メモリ故障に起因 - フェイルオーバー機能せず :Security NEXT のような事例があった。可用性を常に守ることがいかに難しいかを表している)
それを意識した上で、分散 KVS である etcd について説明していく。
etcd の特徴として、2つ挙げられる。
- 高可用性(ただし、一貫性が優先される)
- 強い一貫性
高可用性としては、etcd はクラスタリングを行うことができ、5台のうち最大 2台が壊れた場合でも残りのノードで処理を続行できる。 また強い一貫性というのは、データを読み取り時に etcd はすべてのノードが同じ結果を返せることを保証している。
高い可用性を持ちつつ、強い一貫性はどのように保たれているのか?
Raft について
etcd は Raft と呼ばれる分散合意 (Consensus) アルゴリズムに基づいて実装されている(Raft Consensus Algorithm)。 公式ページの冒頭にあるように「Raft は簡単に理解ができるようにデザインされている」。
*下記の説明について、Raft の論文 を読むと正確かつ詳細がわかる。読みやすい論文なのでおすすめです。
合意(Consensus) について
合意は何かというと「複数の server が問題ないと判断した値を最終結果として考える」ことだ。 ここで、server は Raft の構成要素であり、server は後述のステートマシンとログを持つ。
etcd が 5台のうち最大 2台が壊れた場合でも処理が行えるのは、クラスタを構成するノードのうち、多数が生きていれば合意を行なって結果を返せるからだ。
一般に合意アルゴリズムは複製されたステートマシンの文脈で利用されることが多い。 ここでいうステートマシンは例えば hash table のようなデータだ。 (大学の情報科学の講義で学んだ 有限オートマトン - Wikipedia のような話が出てくるのが面白い)
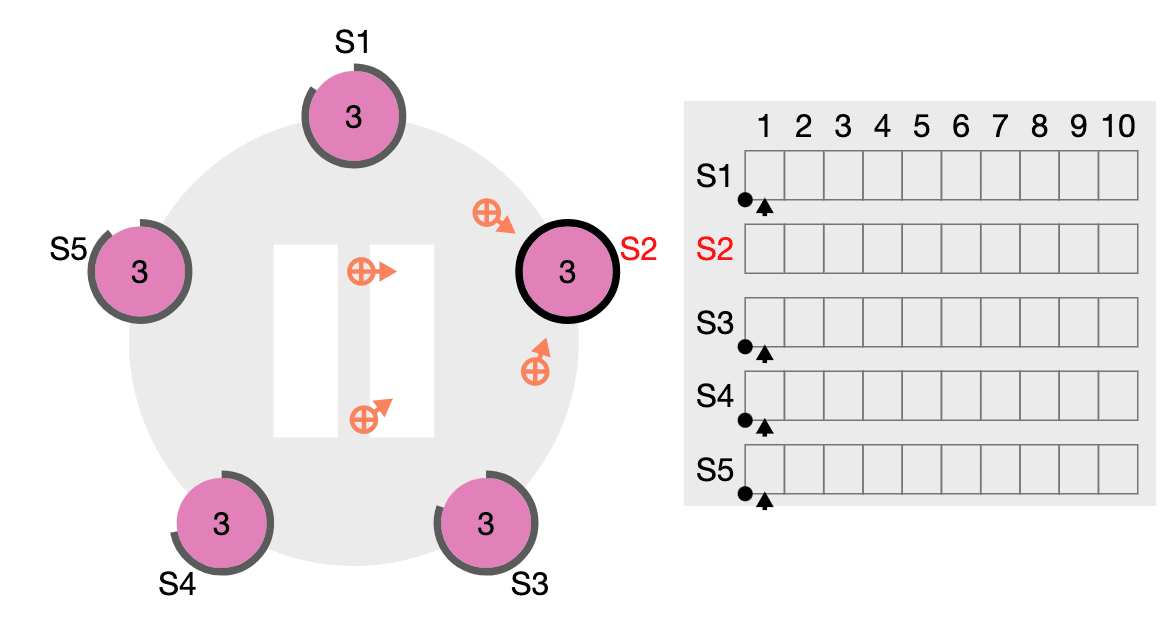
合意した結果をクライアント側では受け取るが、このときクライアントからは1つのステートマシンの状態を受け取っているように観測される(内部的には複数の server が落ちていても Consensus によって隠蔽化されている)。
各ステートマシンはそれぞれログから入力を得る。 ここでいうログは、一般的なアクセスログのようなものではなく、「set x to 3」のような書き込みコマンドのキューを指す。
合意が決まった場合は、n回目のコマンド実行にて、どのステートマシンも同じコマンドを適用しなければならない。 強い一貫性を保つために、一匹狼のようなステートマシンは許さないということだ(一貫性が壊れてしまう)。
リーダーについて
さて、合意するにも「誰がクライアントから書き込みのリクエスト(Raft でいうログ)を受け取り、結果をクライアントに返すのか」を決める必要がある。 (スイスの直接民主主義選挙の様子を思い出した)

合意の中で取りまとめ役を行うのがリーダーだ。 リーダーはクライアントからログエントリーを受け取って、すべての server に複製し、そのログエントリーを適用するタイミングを全 server に伝える。
リーダーを定義することによって、ログエントリーの扱い方がとてもシンプルになり、また合意する問題を 3 つの独立した問題に分けることができる。
- リーダー選出
- ログの複製
- ログエントリー書き込みの一貫性維持(原文では Safety)
1. リーダー選出
各 server は 3つの役割のいずれかとなる。これらの単語は etcd のログの中でも出てくる。
- リーダー(leader)
- フォロワー(follower)
- 候補者(candidate)
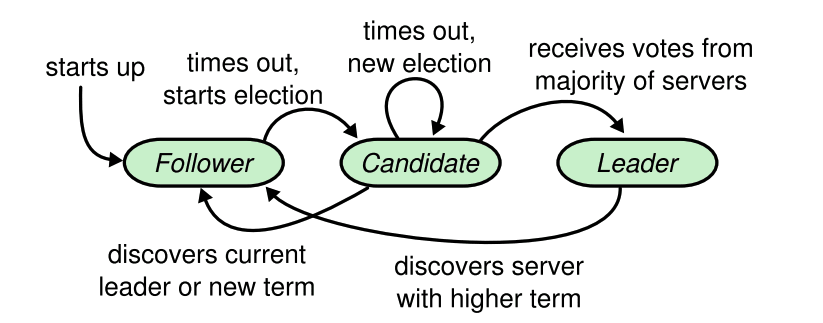
通常は、1つの server がリーダー、残りの server がフォロワーという状態となる。 フォロワーは基本的に受け身でリーダーや候補者からのリクエストに対して受け答えするだけだ。
term (Raft における論理的な期間) が更新されるたびにリーダー選出は行われ、選ばれた候補者がリーダーとなる。 ただし、票が割れた場合には、リーダーの存在しない期間が存在することになる(政治的空白みたいだ)。
最初に Raft クラスタが立ち上がったとき、すべての server はフォロワーから始まる。 この状態では全員がフォロワーのため、ずっと他者(リーダーあるいは候補者)からのリクエストを待ち続け、処理が一向に進まない。ではどうするか?
Raft ではしばらくリクエストが来ない状態を検知すると、いずれかのフォロワーは term をインクリメントし、候補者に成り代わる。 候補者に成り代わったら、自分自身に投票を出しつつ、他の server に対して RequestVoteRPC を出す。
このとき、各 server がランダムな時間で term を更新する (150ms - 300ms) ことで、同時に候補者がいる状態をレアケースとなるようにしている。 もし候補者が複数いて、票がわかれた場合は再選挙となり、この間はクライアントのログエントリーを処理できない(可用性が失われる。CAP定理のとおりだ)
2. ログの複製
リーダーが選出されると、リーダーはクライアント側からのリクエストを受け付けて、残りの server (これらはフォロワーになっている)に対し、ログエントリーを書き込む命令(AppendEntries RPC)を出すようになる。 もしフォロワーの中にクラッシュしたり、処理の遅い server がいたら、リーダーは AppendEntries RPC を無期限に送り続けて、全 server のステートマシンが同期していることを保証する。
強い一貫性が成り立つのはこの仕組みによるためだ。
3. ログエントリー書き込みの一貫性維持
TBD
参考
- etcd | Home
- zoetrope/etcd-book
- Raft Consensus Algorithm
- Raft の論文: In Search of an Understandable Consensus Algorithm
- etcd/raft : etcd にて raft アルゴリズムが実装されているライブラリ
- Paxosアルゴリズム - Wikipedia
- 直接民主主義 - Wikipedia
etcd の運用について
ここまでで、etcd のベースとなる Raft について説明した。Raft によって、高い可用性と強い一貫性を実現している。 注意が必要なのは、ここでも CAP定理は成り立っており、Raft は強い一貫性を優先する代わり、リーダーがいない期間はクライアントのリクエストを処理できない(可用性を犠牲にする)。
そのため、etcd のクラスタが機能しないことは実際ありうるし、自分も etcd を運用していて過去に何度か経験している。 それでは、どうやって etcd が機能するように戻せるのか?
重要なのは、Raft を知った上で etcd がどのような状態になっているのかをメトリクスやログから理解することだ。 (宣伝:SRE では Observability が重要という話 -> 重要さが増すサービスの「信頼性」を高めるためにSREエンジニアたちが続ける挑戦:CodeZine)
etcd は Prometheus のメトリクスエンドポイントを提供おり、様々なメトリクスで内部の状態が分かるようにしている。 どのようなメトリクスが重要かは etcdを監視する方法 | コンテナ・モニタリング | Sysdigブログ という良い記事があるため、割愛する。
例えば、記事にあるように etcd_server_has_leader が 0 になっていれば、再選挙が行われるまで etcd クラスタは機能していない。
では、なぜ no leader になってしまったのかを各 server の情報をもとにトラブルシュートする必要がある。
このとき、node_exporter やジャーナルログなど server 自体の情報を取得しておく必要がある。
状態を持つといかに可用性を保つのが難しいか、身を染みて実感する…
おまけ: ステートフルなコンポーネントはできるなら集約する
一貫性を保ちながら、できるだけ可用性を保つことはここまでの長文の通り、一筋縄ではいかない。 そのため、システムの設計パターンとして、ステートフルなコンポーネントは集約する という考え方がある。
具体的には、Kubernetes のようにステートフルな役割は etcd に任せてしまい、残りはステートレスに作る。 これによって、他のコンポーネントの可用性に対する考慮をぐっと減らせることができる(最初のフロントエンド、バックエンド API について思い出してほしい)。
ただし、etcd には保存できるデータサイズの上限があったり、スケールアウトによる性能改善はできず、スケールアップするしかない制限がある。
結局のところ、システム設計に銀の弾丸はなく、ビジネス要件に応じて適切なデータベース選択をする必要がある。 ということは、データベースにどっぷり浸かったコードがビジネスリスクに発展することもあるわけだ。