Go言語の Garbage Collector を理解したい
プログラミング言語を理解していく上で、その言語のランタイムの特性を把握するのは非常に大切。 Go 言語を理解するために、Go の GC が何を行っているのかを知りたい。
まずそもそも GC (Garbage Collection) とは何か?
GC はメモリの管理を自動にし、mutator が作成し不要になった object を削除すること。
object とは?
GC でいうところの object はメモリを利用するデータの塊のことを指す。object 内には header が埋め込まれており、object のサイズや種類が入っている。
header には、
- object のサイズ
- object の種類
が書かれていて、GC はこれをもとにどうやって object を開放するかどうか決めている。
mutator とは?
mutator (変化させるもの) は基本的に実行しているアプリケーションプログラムを指す。 mutator は、object を作成したり、object の参照を更新したりする。しかし、object の領域を解放することはしない(それは GC の仕事)。
GC のない言語では、object のメモリ領域の解放もアプリケーションプログラムが行う。(C 入門時に malloc や free 関数を使うのに苦労した記憶が蘇る…) これを GC の対義語として、 manual memory management と言ったりする。
GC のある言語では、mutator が使い終わって不要になった領域を GC が健気に回収していく。 このとき、mutator に利用されている object は live object、そして、不要になった object を dead object と呼ぶ。
chunk とは?
chunk(塊)という言葉は情報工学の中で様々な使われ方をされるが、GC の世界では、将来的に object として利用できる空き領域を指す。
memory heap の中でまず mutator が起動する前は chunk の状態から始まる。 そこから、live object が作られ、その後 dead object になり、GC がそれを回収して chunk に戻る、というライフサイクルを送る。
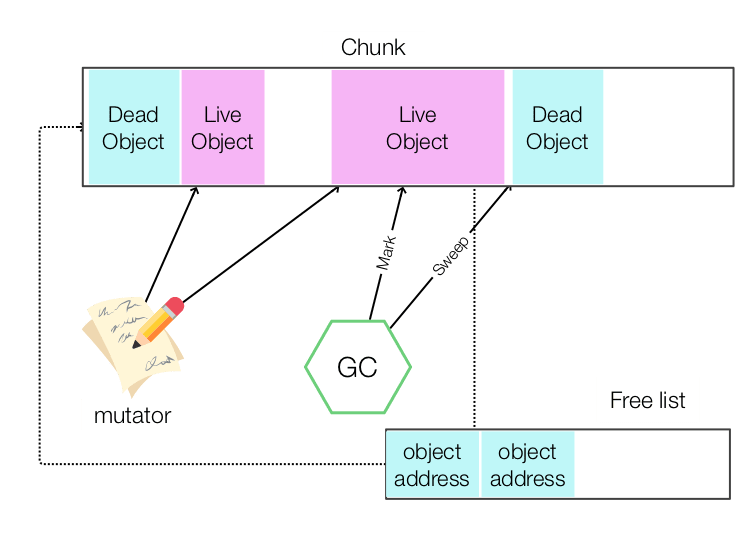
GC の基本 Mark & Sweep
Mark & Sweep アルゴリズムは、live object を Mark するフェーズと Mark されていない dead object を Sweep するフェーズにわかれる。
Mark フェーズでは、すべての root をなめていき、利用されている object にマークをつけていく。このとき、object が Mark 済みかどうかフラグをつけることで、無限ループへ陥らないようにする。
面白いのは、この root をなめていく処理の際、object 参照を探索していくため、幅優先探索か深さ優先探索を行う。しかし、深さ優先探索のほうがメモリ使用率は少ないため、よく使われる。 GC も自身のメモリ消費を気をつけないといけないのだ。
Sweep フェーズでは、heap の先頭から object が Mark されているかどうかを調べていき、Mark されていない object については、free list に追加する。 そうすることで、次に mutator から chunk が求められたとき、free list の中から求められたサイズにあった object を返して、mutator はそれを利用できる。
参考
Go言語の GC について
(Getting to Go: The Journey of Go’s Garbage Collector - The Go Blog を抄訳しつつ、自分なりの理解を補足します)
Go のプログラムは膨大な数のスタックがあり、これらは Go scheduler によって管理され、GC safepoint にて差し替えられる。 Go scheduler は数々の goroutine を OS の thread にひもづけて、できるだけ 1 OS thread が 1 HW thread (ここでは CPU の物理的なコアかスレッド)で動作するように調整する。
Go scheduler はスタックとそのサイズ情報をコピーして、スタック内のポインタを更新することによって管理する。
Go scheduler について
にもあるとおり、これはこれでまた長い説明が必要なため、また別の機会とする。
Go は値型中心の言語
多くの参照型中心な managed runtime な言語とはことなり、Go は値型中心な言語だ。 例えば、tar - Golang の構造体について考えてみる。
すべてのフィールドは直接 Reader 構造体の値として埋め込まれている。 このように、プログラマにはメモリのレイアウトについてよりコントロールを与えられる。 例えば、関連する値を持つフィールドを集約でき、その結果、cache locality を高めることができる。
値型中心の設計は Foreign Function Interface (FFI) にも役立つ。 Go には C と C++ の高速な FFI が存在する(cgo)。 Google にはたくさんのソフトウェア資産があるが、それらは C++ で記述されているため、高速な FFI があれば機能の移植が進めやすい(C, C++ は値型中心の言語)
この値型中心な言語仕様が他の GC を持つ言語とは大きく異なる点だ。
FFI
Foreign function interface - Wikipedia
Go のコンパイルについて
Go は ahead of time (AOT) compilation を行う。これにより、生成されたバイナリファイルは native に実行が可能となる。 (Ahead-of-time compilation - Wikipedia。日本語では事前コンパイルと言われたりするようだ)
Go では Just in time (JIT) compilation を実行しないが、これにはメリデメが存在する。
- メリット:プログラムの再現性が JIT compilation と比べてかなり簡単のため、コンパイラの改善がずっと簡単に行える。
- デメリット:JIT のようにプログラム実行時のフィードバック最適化が行えないため、実行速度は JIT ほど出せないことがある。
JIT コンパイルとは
実行時コンパイルで、例えば Java の場合だとソースコードを機械語に変換するのではなく、バイトコードという OS や CPU に依存しない中間言語 (.class) へ変換する。 そして、バイトコードを JVM がプログラム実行時にコンパイルしてメモリに機械語を展開する。
JIT コンパイルの 1つのメリットは、このバイトコードを配布すれば、JVM の動く環境でプログラムが実行できる。 もう 1つのメリットは、実行時の情報をもとに関数のインライン化などの最適化を実施することで AOT コンパイルより速く実行できる(しかし、その代わりプログラムの実行結果の再現を取るのが難しい)
一方で、起動時にバイトコードのコンパイルを実施し始めるため、すぐにサービスインできなかったりする(コンテナ環境ではやや扱いづらい)。
参考
GC を調整するための2つのパラメータ
Go の GC を調整するためのパラメータが2つある。
1つ目は、GCPercent だ。これは、GC にどれほどの CPU と RAM を利用させるかを調整する。 デフォルトは 100 で heap の半分が live memory, 残りの半分が allocation に利用される。
2つ目が、MaxHeap だ。これは、heap の最大値を設定できるようになる。 Out of memory (OOM) は Go では大問題となる。一時的なメモリのスパイクには処理の中断ではなく、CPU コストでカバーしたい。 Go の場合、GC がメモリの上昇を検知した場合、アプリケーションに対して負荷を減らすように通知する。 (メモリを守るように動作する)
MaxHeap はメモリのスケジューリングにもより柔軟性をもたせる。 heap サイズの上限を定めることで、runtime はどれほどメモリが使えるのかいつも気にしなくてよくなり、MaxHeap まで利用するという判断を下せる。
Go の runtime の歴史
2014 年 Go にとって GC の遅延が脅威だった
2014 年の段階で、GC の遅延が Go の存在意義に関わる脅威であった。
他の新しい言語も同じ問題に抱えており、例えば Rust は別の方法でその問題に対応した(FYI: RustはGCなしでどうやってヒープを管理しているかのメモ – ukitaka – iOS開発とかのメモ)
GC の遅延は積み重なる
例えば、Go のサーバで 100 リクエストを捌くとする。
99 パーセンタイルのユーザに対して、GC の処理時間を 10ms に抑えようとすると、GC が利用できる時間は 1% ではなく、実際は 0.01 % に抑える必要があった。 (Google の規模の処理を実施するためにはこれほどまでに突き詰めた性能が必要であり、これを「暴虐な9s (tyranny of the 9s) 問題」と Google 内では呼んだそうな。99.99% を GC 以外の処理にあてる必要があったため)
そもそもなんで 99 パーセンタイルというような高い指標を達成する必要があったのかというと、Google のスケールとなるとサーバーのスケールアウトでカバーしようにも、新しいデータセンターが必要なくらいコストがかかってしまう。 逆に言えば、このコストが Go の GC をチューニングする良い機会になった。
最初に取り組んだのは、すべての runtime とコンパイラを Go に変えることだった(それまでは C だったが、バグに悩まされた)。
もともとの計画としては、read barrier のない concurrent copying GC を作ろうとしていた。
Copying GC とは?
日本語だとコピーGCという名がついたりする。マービン・ミンスキーが考案したアルゴリズム。
ざっくばらんにいうと、live object だけを別の領域にコピーして、もとの領域にあったオブジェクトすべてを破壊する。 このとき、live object の中身を再帰的にコピーして、「コピーしたかどうか」のフラグをたてていく。移った先の object を向いている必要があるため、コピーが完了したら新しいアドレスを返していく。
Heap の半分を From領域、もう半分を To領域として使うため、メモリの利用効率としてはよくないが、To領域には live object のみが順に並び、From領域全体が chunk になるため、新しい object のアロケーションが速い。 (実質、From -> To へ移すときに compaction を実施している)
さらに、To領域で live object とその子 object が近くに並ぶことにより、CPU のキャッシュメモリでのヒット率を高めることができる(コピーGC のアルゴリズムによる)。
read barrier とは
GC ではここまで記述したように、object のポインタの付け替えが行われる。その際に、古いポインタを mutator が読んでしまわないようにするのが read barrier。
concurrent GC
mutator が稼働しながらも GC を行う。concurrent は「同時に」という意味。
しかし、完全に concurrent にできるわけではなく、GC を実行しているときにはポインタの書き換えがされないように write barrier を実施している(短い時間の STW)
STW (Stop the world) とは?
GC が object の参照状態を一時的にすべて解析し、不要なものを解放する。 その間、新しい object の allocation が行えないため、mutator にとっては「世界が止まった」ように見える。
tri-color アルゴリズムを利用した concurrent GC をつくる
Copying GC の場合は、From -> To へ移す際に object のポインタの付替えを実施する。しかし、前述の FFI のことを考えると、C と Go 間でアドレスの変換をブリッジする必要があり、これはバグのもとになりそうだという背景もあった。 そのため、メモリの compaction を行うのではなく、mark and sweep ベースの GC が作れないか考えた。
Rick Hudson と Eliot Moss は Dijkstra のアルゴリズム (tri-color marking) が複数のアプリケーションスレッド(Go の場合は、Go scheduler の P)で機能することについて証明していた。 また、STW (Stop the world) 問題に対応できることもその研究内でわかっていた。
具体的には、object のサイズ別に分離した span のリストを作成するようにした。これにはいくつかメリットがあった。
- GC は効率よく object のアドレスの先頭を見つける必要があるが、サイズ別に分けられていれば、どこが先頭かすぐに分かる
- フラグメンテーションを低減できる
Copying GC と比べると memory allocation の遅さはたしかにあるのだが、C と同じオーダーくらいの速度であり、FFIのことを考えると十分だった。
これまでの Go GC では object に header がなかった。そこで、object metadata をフィールドに加えた。
object metadata の例。
これらの metadata をつかって、GC を実行する。
tri-color marking GC とは
三色マーキングは object を 3種類に分類する。
- 白:まだ探索されていない object
- グレー:探索途中の object
- 黒:探索済みの object
GC 開始時点では、すべての object が白になっている。つぎに GC が root から object をたどっていって、スタックに積んでいく。
スタックに積まれた object はまだ内部の探索が終わってないため、グレーとなる。
スタックから取り出された object の子objectもスタックに積まれて、グレーとなり、最終的にすべての子objectが探索されたら、黒になる。
tri-color marking GC が完了すると、object は白(探索されない dead object)か黒(探索された live object)になる。
さらに GC Pacer で的確に GC を実施する
ここまでで、Go の GC は値型中心ならではの方法で tri-color marking GC を goroutine を実行させながら処理しているが、さらに GC Pacer によって的確なタイミングで GC を実行するようにしている。
GC Pacer は極力与えられたメモリがなくなりかけたタイミングで、GC が実施されるように調整されている。 具体的には、
- メモリのアロケーションを行う goroutine の処理を止めて、代わりに marking 処理の割合を増やす
- GC の処理が一通り終わったら、その結果に基づき、次の GC のタイミングに活かす
今後の Go GC について
ここまでで Go GC にはかなりの工夫が加えられていることがわかる。 今後の GC の方向性としては、
- Escape analysis を改善する
- write barrier を少なくする
- メモリの増加に期待して、CPU ではなくメモリで改善されるようなアルゴリズムの探求する
とのこと。
Escape analysis とは
Go は極力 object を heap ではなく、stack に入れられないかチェックする。 heap に入れる基準としては、その object が他の stack frame (関数の境界) で共有されるかどうか。
基本的に stack に入っている方が、object を再帰的に探索する必要もなく、Processor ごとに用意された、サイズ別の span に放り込めるため、GC の処理がはやく済む。
参考
- runtime - The Go Programming Language
- Go: How Does the Garbage Collector Mark the Memory?
- Getting to Go: The Journey of Go’s Garbage Collector - The Go Blog
- najeira: Go言語のスタックとヒープ
- Golang Internals, Part 4: Object Files and Function Metadata | Altoros
- Visualizing Garbage Collection Algorithms
- A visual guide to Go Memory Allocator from scratch (Golang)
- Garbage Collection In Go : Part I - Semantics
- Golang Escape Analysis: reduce pressure on GC! - Faun - Medium